Artificial Intelligence has gained huge momentum in recent years, finding its way into nearly every field — and music is no exception. Once limited by creative bottlenecks, AI has transformed how we write lyrics, generate melodies, master audio, and even compose full songs.
Today, there's a wide range of open-source AI music generators available. But with so many options out there, which one should you use?
- DiffRhythm - Best for composers & MIDI creators
- Audiocraft - Best for prompt-based music makers
- Yue AI - Best for vocalists & full-song demos
- Riffusion - Best for ambient / experimental sounds
- Mubert - Best for streamers & royalty-free loops
- Magenta - Best for educators & MIDI experiments
- MusicGen - Best for hobbyists & AI music producers
- ACE-Step - Best for advanced remix & lyric-to-melody
- MusicLM-PyTorch - Best for developers & MusicLM experiments
- OpenAI Jukebox - Best for AI researchers & vocal audio
Open-Source Music Generation Model
In general, six types of AI models power today's music generators — each shines in different areas but comes with its own challenges.
- LLM-Based: Large language models trained to align lyrics, melody, and structure, often integrating text understanding into music creation.
- Diffusion-Based: Gradually converts noise into music via a diffusion process, allowing for fine-grained control over timbre and audio texture.
- Transformer-Based: Uses transformer architectures to model long-term dependencies in sequences (notes, tokens, or compressed audio).
- Spectrogram/Diffusion Hybrid: Converts text prompts into spectrograms using Stable Diffusion, then back into audio — bridging image generation and sound synthesis.
- Autoencoder and VAE-Based: Use autoencoders or VAEs (Variational Autoencoders) to compress and reconstruct musical patterns efficiently, enabling style transfer and loop generation.
- Hybrid Architectures: Combines multiple architectures — transformers + diffusion + autoencoders — for end-to-end generation from text to waveform.
|
Model Type
|
Example Tools
|
Main Strength
|
Main Weakness
|
|
LLM-Based
|
Yue AI, ACE-Step
|
Strong lyric & emotion alignment
|
Slow and GPU-heavy
|
|
Diffusion-Based
|
DiffRhythm, AudioCraft
|
Realistic timbre & fast synthesis
|
Weak long-range structure
|
|
Transformer-Based
|
MusicGen, Magenta, Jukebox, MusicLM-PyTorch
|
Coherent structure, scalable
|
Resource-intensive
|
|
Spectrogram Hybrid
|
Riffusion
|
Fast, flexible text-to-music
|
Limited temporal coherence
|
|
Autoencoder/VAE
|
Mubert, EnCodec
|
Efficient loops & textures
|
Repetitive or simple outputs
|
|
Hybrid (Multi-model)
|
AudioCraft, Jukebox
|
End-to-end realism
|
Complex setup & huge models
|
DiffRhythm
- 🔗URL: https://diffrhythm.com/ai-music-generator
- 🌐Status: Active
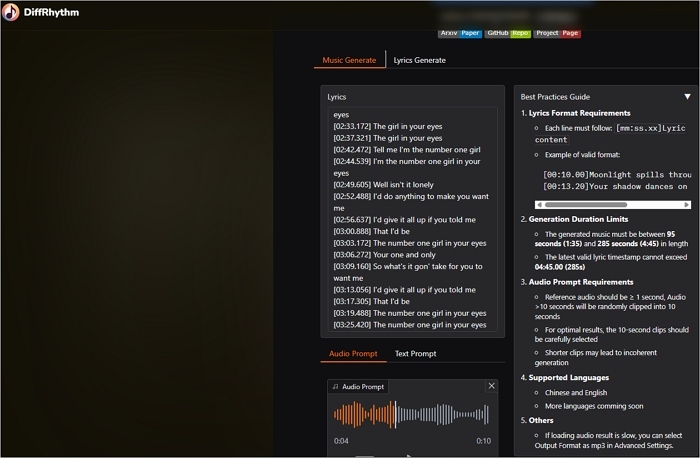
DiffRhythm is the first open-source, latent diffusion–based song generator that uses a non-autoregressive architecture to produce full-length songs quickly and with high quality, complete with synchronized vocals and instrumentals. Trained on a massive dataset of 1 million songs, DiffRhythm supports multiple musical styles, allowing users to generate music simply by providing lyrics and a style prompt.
![open-source-ai-music-generator-diffrhythm.jpg]()
| ⭕Pros |
❌Cons |
- Fast generation with vocals and accompaniment.
- Produces professional-level instrumental backing and vocals.
- Simple use without complicated pre-up.
- Multi-language support.
|
- Lack advanced controls for detailed editing.
- Repetitive signature tone over time.
- Vocals and lyrics may not always align perfectly with the generated music.
|
AudioCraft
- 🔗URL: https://github.com/facebookresearch/audiocraft
- 🌐Status: Active
AudioCraft is a PyTorch library for deep learning research on audio generation, developed by Meta. It includes both inference and training code for state-of-the-art AI generative models such as AudioGen, MusicGen, EnCodec, Multi-Band Diffusion, and more. Users can also develop their own training pipelines, making it ideal for hobbyists and creators who want AI to follow text prompts or reference audio.
| ⭕Pros |
❌Cons |
- Produces realistic audio and music from text prompts.
- Great for generating quick ideas, samples, and inspiration.
- Suitable for creating soundscapes, musical compositions, and audio effects.
- Open and flexible, providing transparency for developers.
|
- Requires technical knowledge to deploy and use effectively.
- Can struggle with generating fully coherent melodies.
- Performance depends heavily on hardware capabilities.
|
Yue AI
- 🔗URL: https://github.com/multimodal-art-projection/YuE
- 🌐Status: Active
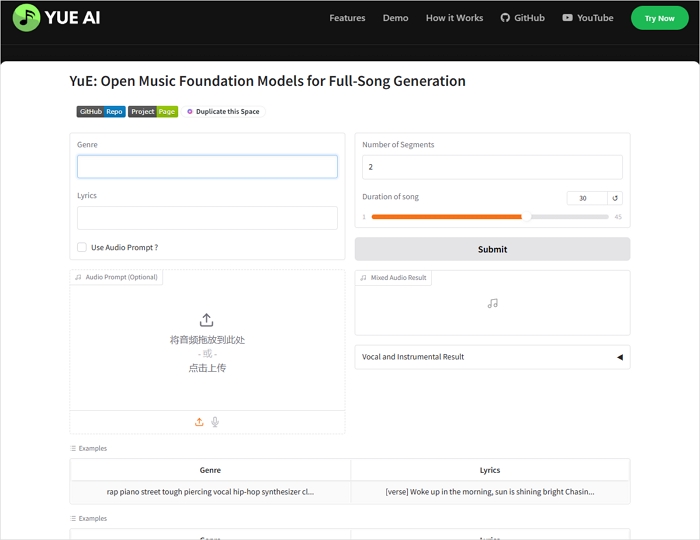
Yue AI generates high-quality music up to 5 minutes with synchronized vocals and accompaniment directly from lyrics, maintaining musical coherence. Like DiffRhythm, it supports multiple languages and music genres like EDM. Its models handle lyrical production, instruments, and genre, and it provides advanced vocal fine-tuning, including timing, pitch, and emotional expression. Yue AI also automatically generates matching instrumental accompaniment and semantic composition that understands the lyrical context.
![open-source-ai-music-generator-yueai.jpg]()
While powerful, Yue AI is aimed at professional users, as the full version requires a minimum of 24GB VRAM, though smaller packages exist with reduced audio quality and slower generation.
| ⭕Pros |
❌Cons |
- Capable of generating complete songs with vocals and accompaniment.
- Supports multiple languages and musical genres.
- Advanced vocal fine-tuning: timing, pitch, and emotional expression.
- Allows for customization and experimentation with lyrics, instruments, and style.
- Semantic understanding ensures instrumental tracks align with lyrical context.
|
- Requires high computational resources, especially for long tracks.
- Generation times and quality can vary depending on hardware.
- Smaller packages have slower generation and reduced audio fidelity.
|
Riffusion
- 🔗URL: https://github.com/riffusion/riffusion-hobby
- 🌐Status: No longer actively maintained.
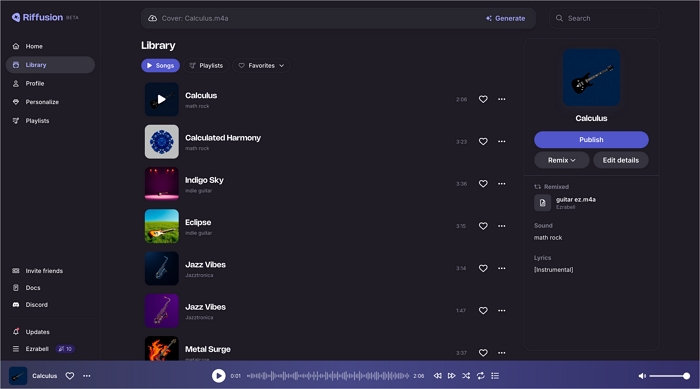
Riffusion is a real-time music and audio generation library powered by Stable Diffusion. It supports text-to-music, lyrics-to-song, AI covers, audio conditioning, music extension, and section replacement across a wide range of music genres. The platform also includes social user profiles and community tracks, allowing users to explore and share creative outputs.
![open-source-ai-music-generator-riffusion.jpg]()
Riffusion stands out for its highly polished sound quality and intuitive, user-friendly interface, making it appealing to both beginners and casual creators. However, the free version offers limited features, and users have noted occasional inconsistencies in prompt adherence, particularly in vocal style or language generation.
| ⭕Pros |
❌Cons |
- Supports real-time text-to-music and lyrics-to-song generation.
- Clean, accessible UI ideal for beginners and hobbyists.
- Community integration encourages sharing and collaboration.
- Produces high-quality, polished audio outputs.
- Offers a wide range of genres and creative tools.
|
- Free version limitations restrict creative flexibility.
- May ignore certain prompts or vocal instructions.
- Inconsistent output quality depending on the prompt complexity.
|
Mubert
- 🔗URL: GitHub: https://github.com/MubertAI/Mubert-Text-to-Music API: https://mubert.com/render/text-to-music
- 🌐Status: Active
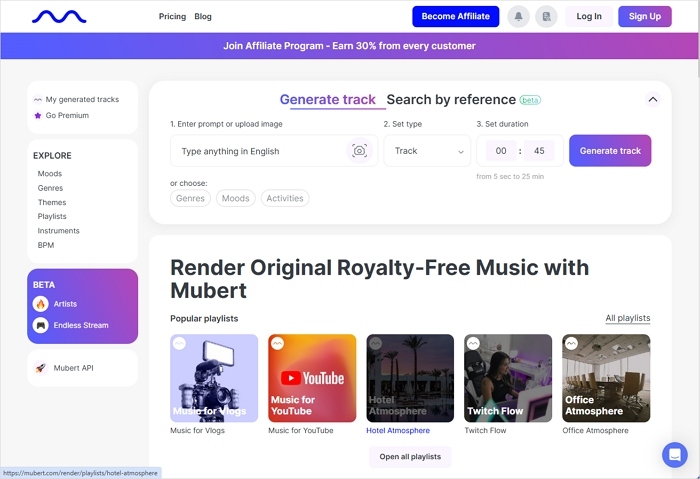
Mubert is a royalty-free AI music generator that transforms text prompts or images into full-length music tracks. Users can define the mood, genre, theme, instruments, BPM, and duration to generate tailored compositions. It also offers an API for developers, making it suitable for integration into creative or GitHub projects like Mubert Text-to-Music.
![open-source-ai-music-generator-mubert.jpg]()
Free users receive 25 track generations, 10 downloads per month, and 30 minutes of daily generation time, though some advanced features remain exclusive to business plans.
| ⭕Pros |
❌Cons |
- Converts text or image prompts into high-quality music.
- Covers 150+ genres and moods for flexible creation.
- Supports tracks ranging from 15 seconds to 25 minutes.
- Includes a 12,000+ pre-generated song library.
- Offers precise control over parameters like BPM and style.
|
- Free plan is limited in track generation and downloads.
- Full feature access, including in-app music use, requires a paid plan.
|
Magenta
- 🔗URL: https://github.com/magenta/magenta
- 🌐Status: Currently inactive
Magenta is an open-source AI music and art generation project by Google, built on TensorFlow. It focuses on exploring how machine learning can enhance human creativity through tools that generate melodies, harmonies, rhythms, and instrumental sounds. Developers and musicians can use Magenta's pretrained models, plugins, and notebooks to experiment with music composition, improvisation, and live performance.
| ⭕Pros |
❌Cons |
- Highly flexible and extensible for developers and researchers.
- Offers a range of pretrained models for melody, rhythm, and sound generation.
- Integrates easily with DAWs (like Ableton Live) through the Magenta Studio plugin.
- Ideal for music research, education, and creative prototyping.
- Strong community support and continuous updates.
|
- Requires technical setup and coding skills to use effectively.
- Output may sound less polished compared to newer diffusion-based models.
- Limited real-time generation features without additional integration.
|
MusicGen
- 🔗URL: https://musicgen.com/
- 🌐Status: Active
MusicGen is an open-source text-to-music model developed by Meta, designed to generate high-fidelity music directly from text or melody prompts. It can take a short melody as input and expand it into a full composition, making it especially useful for musicians, producers, and AI music researchers. The model is trained on licensed music data, ensuring quality and originality.
| ⭕Pros |
❌Cons |
- Produces realistic, high-quality music from simple text or melody inputs.
- Open-source and available for research or creative projects.
- Offers fine control over generation using conditioning on melody or style.
- Lightweight and accessible, runs efficiently on consumer GPUs.
- Backed by Meta's research team with solid documentation.
|
- Limited vocal generation (mostly instrumental).
- Less suitable for complete songs or lyrics-based projects.
- May require technical familiarity with Python or Hugging Face for setup.
|
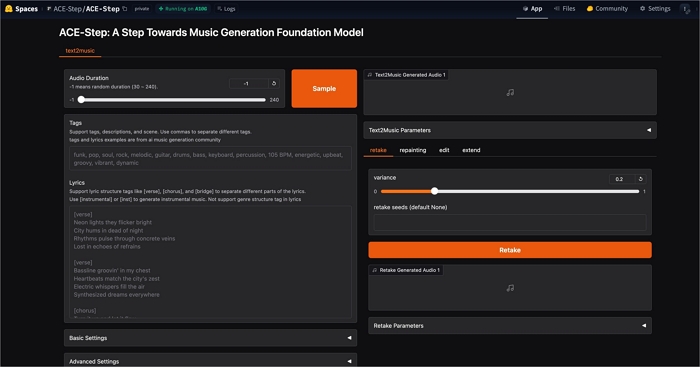
ACE-Step
- 🔗URL: GitHub: https://github.com/ace-step/ACE-Step Online: https://acestep.io/
- 🌐Status: Active
ACE-Step is an open-source AI music generation model designed to overcome the traditional trade-offs between generation speed, musical coherence, and controllability. It integrates a diffusion-based model, a deep compression AutoEncoder, and a lightweight linear transformer, enabling fast and coherent music creation.
![open-source-ai-music-generator-ace-step.jpg]()
ACE-Step can generate a 4-minute song in just 20 seconds while maintaining strong musical structure and detail. It also provides fine-grained acoustic control, supporting advanced tasks like voice cloning, lyric editing, remixing, and track-level generation — making it one of the most versatile frameworks for research and production.
| ⭕Pros |
❌Cons |
- Combines Stable Diffusion, AutoEncoder, and transformer architectures for balanced performance.
- Extremely fast synthesis (4-minute track in ~20 seconds).
- Maintains long-range musical coherence despite speed.
- Provides fine acoustic control over vocals, lyrics, and arrangement.
- Supports multiple use cases — text-to-music, lyric-to-vocal, remixing, and track generation.
|
- Complex to deploy and requires a powerful GPU setup.
- Not beginner-friendly — geared toward developers and researchers.
- Quality varies with random seeds and input length.
- Weaker performance on niche genres like Chinese rap.
- Occasional unnatural shifts during extension or remixing.
- Lacks expressive depth in synthesized singing.
- Needs finer adjustment for musical parameters.
- Demands advanced setup and strong GPU resources.
|
MusicLM-PyTorch
- 🔗URL: https://github.com/lucidrains/musiclm-pytorch
- 🌐Status: Active
MusicLM-PyTorch is an open-source PyTorch implementation of Google's MusicLM, a powerful text-to-music generation model that creates coherent audio from natural language prompts. It builds upon AudioLM and SoundStream architectures, using hierarchical transformers to model both high-level musical structure and fine-grained audio details.
![open-source-ai-music-generator-musiclm-pytorch.jpg]()
While not officially released by Google, this PyTorch reimplementation allows developers and researchers to experiment with MusicLM-like capabilities locally or via Colab.
| ⭕Pros |
❌Cons |
- Faithful PyTorch replication of Google's MusicLM.
- Generates coherent, long-form music from text prompts.
- Supports fine control over musical semantics and structure.
- Research-friendly and open to customization or fine-tuning.
|
- Unofficial implementation — may differ from Google's original model performance.
- Requires strong GPUs for real-time or long-form generation.
- Setup complexity and limited documentation for beginners.
- Lacks vocal generation and lyric-to-song capability.
|
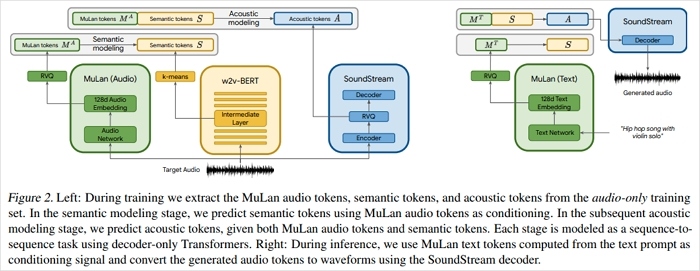
OpenAI Jukebox
- 🔗URL: https://openai.com/index/jukebox/
- 🌐Status: Active
OpenAI Jukebox is a neural network model that generates high-quality music with vocals, spanning various genres and artist styles. It works directly on raw audio rather than symbolic formats like MIDI. The process involves:
- Hierarchical VQ-VAE: Compresses audio into discrete latent codes at three levels, preserving essential features such as pitch, timbre, and rhythm while reducing data size.
- Autoregressive Transformers: Each level predicts sequences of codes; the top-level transformer captures high-level structure, while lower levels refine the audio details.
- Extensive Training Dataset: Trained on 1.2 million songs, including English tracks with lyrics and metadata from LyricWiki, allowing it to generate music in diverse genres and styles.
| ⭕Pros |
❌Cons |
- Generates long-form, coherent music with vocals and high audio fidelity.
- Can be conditioned on artist, genre, and lyrics for stylistic control.
- Open-source model weights allow research and experimentation.
- Innovative combination of VQ-VAE compression and hierarchical transformers ensures realistic outputs.
|
- Generating music requires substantial GPU resources.
- Outputs may not always perfectly match prompts.
- Still less nuanced than human compositions in terms of structure and emotional depth.
|
Online AI Music Generator Without Installation
Open-source music generators are free, open to customization, but they are also complicated to employ, and some require code for generation, which makes online AI music generators shine due to their easy UI and workflow without downloading.
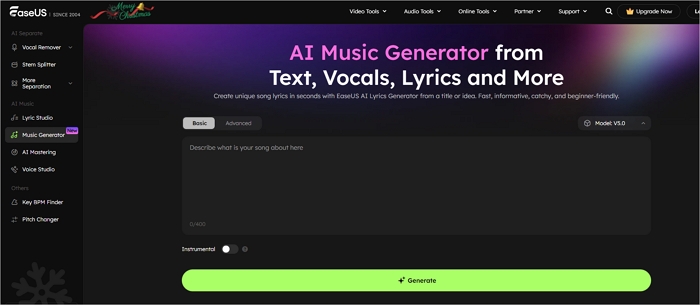
EaseUS Online AI Music Generator is a top choice for one-click AI song generation in different music styles and melodies. Users can generate music from text descriptions, lyrics, vocals, and instrumentals, covering genres such as house, rap, R&B, and more. The platform also allows detailed customization of tempo, key, time signature, and other musical parameters, enabling precise optimization. With its world-class AI model, EaseUS delivers full-length, high-quality music quickly and effortlessly.
![easeus-ai-music-generator.jpg]()
Key Features
- One-Click Music Generation: Instantly create songs from text, lyrics, or melody prompts.
- Multi-Genre Support: Generate music in-house, rap, R&B, pop, and other styles.
- Vocal & Instrumental Options: Produce tracks with or without vocals.
- Customizable Musical Parameters: Adjust tempo, key, time signature, and range for precise control.
- Full-Length Tracks: Generate complete songs quickly with high audio quality.
- User-Friendly Interface: No coding or downloads required — designed for ease of use.
- Fast & Reliable: Powered by a world-class AI model for speedy generation.
Wrapping up
Open-source AI music generators like DiffRhythm, Yue AI, MusicGen, ACE-Step, and OpenAI Jukebox offer powerful, flexible tools for creating music, each with its own strengths and limitations. While free and customizable, they often require coding skills and high-end hardware.
For quick, full-length music creation with an easy-to-use interface, EaseUS Online AI Music Generator is a top choice for generating songs from text, lyrics, vocals, and instruments in just a few clicks.
FAQ
1. Is there an open source AI music generator?
Yes, there are several open source AI music generators:
- MusicGen
- Riffusion
- DiffRhythm
- Yue AI
- Audiocraft
2. Is there a completely free AI music generator?
Yes, some completely free AI music generators include:
- MusicHero – 100% free, no login.
- Fotor AI Music Generator – free and royalty-free.
- AIMusic.so – free to use without signup.
3. Is Suno AI still free?
Yes, Suno AI is still free, but with limits:
- You get 50 free credits per day (around 10 songs).
- Uses the v3.5 model in the free plan.
- Non-commercial use only — you can't sell or monetize those songs.
- Paid plans unlock newer models (like v4.5), longer songs, and commercial rights.
4. Can OpenAI generate music?
OpenAI Jukebox is an AI model that creates complete songs—including vocals and instruments—entirely from scratch. Unlike text-to-music tools that convert prompts into melodies, Jukebox directly generates raw audio, capturing details like rhythm, harmony, and vocal tone across many music styles.