Breaking AI's Ears: Songs That Defeat Vocal Separation
Discover why certain songs consistently defeat AI vocal separation tools. Learn which tracks challenge AI and how to improve your separation results.

Page Table of Contents
Discover why certain songs consistently defeat AI vocal separation tools. Learn which tracks challenge AI and how to improve your separation results.
AI vocal separation tools have revolutionized music production and content creation. From TikTok remixes to YouTube covers, creators rely on these powerful algorithms to extract vocals or instrumentals from any song. But here's the thing: certain tracks consistently leave even the most advanced AI models scrambling for answers.
These "AI-resistant" songs expose the fascinating limitations of current vocal separation technology. Understanding why some tracks defeat AI vocal separation can help you choose the right tools, set realistic expectations, and even improve your results when working with challenging audio.
AI vocal separation relies on deep learning algorithms combined with sophisticated audio signal processing. The core principle is surprisingly straightforward: models analyze frequency patterns and audio characteristics to predict which parts of each audio frame contain vocals versus instrumental backing.
Think of it like teaching a computer to recognize different voices in a crowded room. The AI learns to identify vocal patterns—frequency ranges, harmonic structures, and tonal qualities—that distinguish human voices from instruments.
Several powerful tools dominate the vocal separation landscape:
Spleeter (by Deezer) uses convolutional neural networks to split audio into 2, 4, or 5 stems. It's fast, open-source, and widely adopted by individual creators.

Demucs operates directly in the time domain, utilizing end-to-end processing that avoids frequency transformations, which can introduce artifacts. This approach often produces more natural-sounding results.

LALAL.AI and similar commercial platforms utilize transformer-based neural networks with hybrid time-frequency processing, offering user-friendly interfaces for quick vocal extraction.
Each model has unique strengths, but they all share similar fundamental limitations when confronted with certain types of audio.
The magic behind vocal separation becomes less magical when you understand its core vulnerabilities. AI models struggle with specific audio characteristics that create confusion in their pattern recognition systems.
The biggest challenge occurs when vocals and instruments occupy similar frequency ranges. Human voices typically span 85-255 Hz for fundamental frequencies, but harmonics extend much higher. When guitars, keyboards, or other instruments operate in these same ranges, AI models struggle to distinguish between sources.
Consider Queen's "Bohemian Rhapsody"—the multi-layered guitar harmonies occupy frequencies that overlap significantly with vocal ranges. The AI literally cannot determine where Freddie Mercury's voice ends and Brian May's guitar begins.
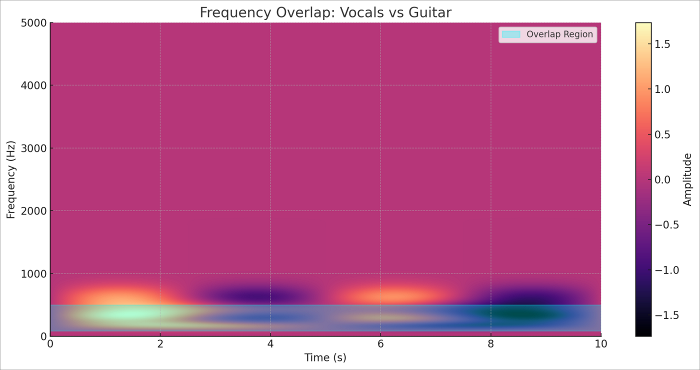
Songs featuring vocoders, auto-tune, or heavy electronic processing present unique challenges. Daft Punk's catalog consistently defeats vocal separation because their robotic vocal effects occupy similar frequency spaces as synthesizers and electronic instruments.
The AI was trained to recognize "natural" human voices, so when vocals are electronically modified to sound mechanical, the model misclassifies them as instruments.
Multiple vocal layers, extensive harmonies, and heavy reverb create what audio engineers call "spectral smearing." Songs like Jamiroquai's "Virtual Insanity" feature intricate vocal arrangements with natural reverb that makes individual voice tracks blend seamlessly into the instrumental mix.
AI models excel at identifying isolated, dry vocals. But when voices blend together or are drenched in natural room acoustics, the separation becomes exponentially more difficult.
Lower-quality audio sources introduce compression artifacts and frequency distortions that confuse AI algorithms. MP3 files at 128 kbps or lower often contain digital artifacts that the AI interprets as additional audio sources, leading to incomplete separation and residual noise.
Certain tracks have become notorious for breaking vocal separation tools. Here's why these specific songs pose such challenges:
Queen - "Bohemian Rhapsody": Multi-tracked vocals, complex guitar harmonies, and overlapping frequency content create an impossible puzzle for current AI models.
Daft Punk - "Within": Heavy vocoder use makes vocals indistinguishable from synthesized instruments in the frequency domain.
Night Lovell - "Dark Light": The deep, processed vocals blend seamlessly with the dark, bass-heavy instrumental, making it nearly impossible to separate them.
Bob Marley - "Sun Is Shining": Natural reggae mixing techniques and organic studio reverb create frequency overlap that confuses separation algorithms.
Artists like Beyoncé, J Dilla, and Eminem also frequently appear on "difficult separation" lists due to their sophisticated production techniques and layered vocal arrangements.
When AI vocal separation fails, it's not random. There are predictable patterns. Audio engineers and researchers have identified specific characteristics that consistently cause problems:
Spectral Bleeding occurs when frequencies from different sources overlap so significantly that even advanced algorithms cannot distinguish between them. This isn't a limitation of current technology—it's a fundamental challenge in audio source separation.
Artifacts and Residual Noise appear when AI models make incorrect predictions about which frequencies belong to vocals versus instruments. These artifacts create the characteristic "robotic" or "underwater" sound often heard in extracted vocals.
Phase Relationships between different audio sources can create cancellation effects that make certain frequencies disappear entirely during separation, leading to thin or incomplete vocal extractions.
The limitations of AI vocal separation aren't just theoretical—they're experienced daily by content creators and audio professionals. Users frequently report that extracted vocals sound artificial, with noticeable artifacts that weren't present in the original recordings.
One audio engineer noted that "AI separation isn't phase cancellation—it's model prediction. The artifacts you hear are literally the AI's best guesses about what should be vocals versus instruments."
These imperfections become particularly problematic when AI-extracted vocals are used to judge artist performance, as seen in viral social media criticisms that may be based on flawed separations rather than actual vocal quality.
While some songs will always challenge AI separation, several strategies can significantly improve your results:
Start with High-Quality Sources: Use WAV or FLAC files instead of compressed MP3s. Higher bitrates preserve more frequency information that AI models need for accurate separation.
Choose the Right Tool: Different models excel with different types of music. Demucs works well for complex arrangements, while Spleeter excels at straightforward pop tracks.
Post-Processing Refinement: Use EQ, noise gates, and manual editing to clean up AI-extracted stems. The AI does the heavy lifting, but human refinement often produces professional results.
Understand Your Source Material: Recognize which songs are likely to cause problems before processing them. Electronic music, heavily produced tracks, and songs with extensive vocal harmonies will require more post-processing work.
AI vocal separation relies on pattern recognition to distinguish between different audio sources. When vocals and instruments share similar frequency characteristics or when audio quality is compromised, the AI cannot reliably differentiate between sources. It's making educated guesses based on training data, not performing perfect mathematical separation.
Electronic music, heavily produced pop, reggae with natural reverb, and orchestral pieces with complex arrangements typically challenge AI separation tools. Genres with clear, isolated vocals and distinct instrumental parts work best.
No current AI tool can perfectly handle all types of music. However, using high-quality source material, choosing appropriate tools for specific genres, and combining AI separation with manual post-processing can significantly improve results.
Commercial tools like LALAL.AI and professional software often handle complex material better than free alternatives, but no tool eliminates the fundamental challenges posed by frequency overlap and production complexity.
Current AI vocal separation technology represents remarkable progress in audio processing, but it's far from perfect. Understanding these limitations helps set realistic expectations and choose appropriate tools for specific applications.
As AI models continue evolving, we're seeing improvements in handling complex audio scenarios. Hybrid approaches that combine multiple separation techniques show promise for addressing current limitations.
For now, the key is recognizing that AI vocal separation is a powerful tool with specific strengths and weaknesses. By understanding what causes separation to fail, you can work more effectively with these technologies and achieve better results in your audio projects.
Remember: AI doesn't replace human expertise in audio engineering—it augments it. The most successful applications combine AI efficiency with human creativity and technical knowledge.


Learn the 4-step formula to identify any music genre by ear. Master rhythm, instruments, vocals & structure to become a music genre guru fast.…
Discover the top 10 easy piano songs for beginners, including pop, Christmas, jazz, classical, and fun tracks. Learn simple chords, practice tips, and how to play your favorite tunes effortlessly.…

Explore the differences between K-Pop, J-Pop, and C-Pop—from their history and music style to industry models and global strategies. Discover how Asia's pop powerhouses are reshaping the world stage.…
Copyright © 2004 - 2025 EaseUS. All rights reserved.